LEARNING VISUAL WORDS WEIGHTS FOR PLACE RECOGNITION
ABSTRACT
The bag-of-words (BoW) paradigm is widely and successfully
used in many visual recognition and retrieval applications.
We present a novel algorithm for improving the performance
of the BoW model by learning discriminatively the
weights of visual words. This learning approach, based on the
large margin paradigm, relies on an efficient stochastic gradient
descent method in the training phase. We demonstrate
the effectiveness of the proposed algorithm applied to place
recognition, a fundamental task in the context of Simultaneous
Localization And Mapping systems in robotics. Experimental
results on publicly available datasets show how, with
learned weights, the place recognition results are more accurate
than with traditional BoW model.
EXPERIMENTAL RESULTS
We tested the proposed approach on three datasets. In
particular we used some synthetic data to demonstrate the
effectiveness of the learning algorithm. Then we performed
loop closure experiments on two publicly available datasets:
the Bicocca dataset from the RAWSEEDS FP6 EU project1
and the MALAGA dataset 2009.
Synthetic Data
This series of experiments shows that the proposed Algorithm
(1) correctly learns a set of weights, enhancing the contribution
of discriminative features and down-weighting the
others. We considered a three class categorization problem.
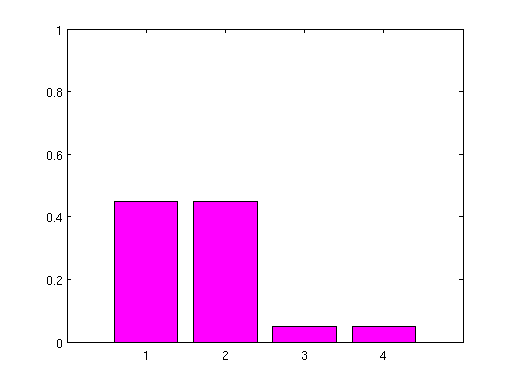
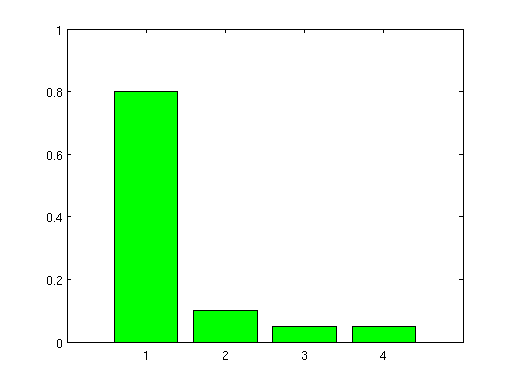
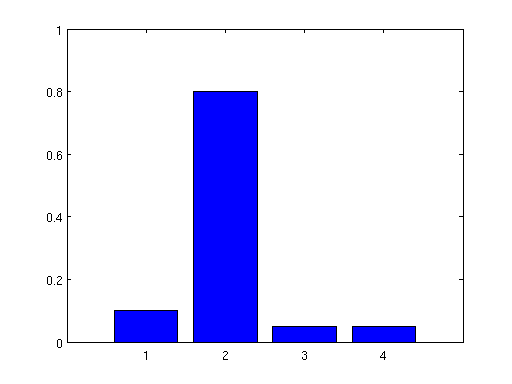
Given the three histograms in Fig.1 we randomly generated
some pairs of training/test sets of histograms by adding to the
coordinates of the original histograms some random noise.
Then we used the proposed algorithm and the approach
presented in [7] to learn optimal weights in order to retrieve
the correct histogram class.
Fig.1: Histograms used in the toy data experiments
Histogram intersection was used
for histogram comparison. The recognition accuracy obtained
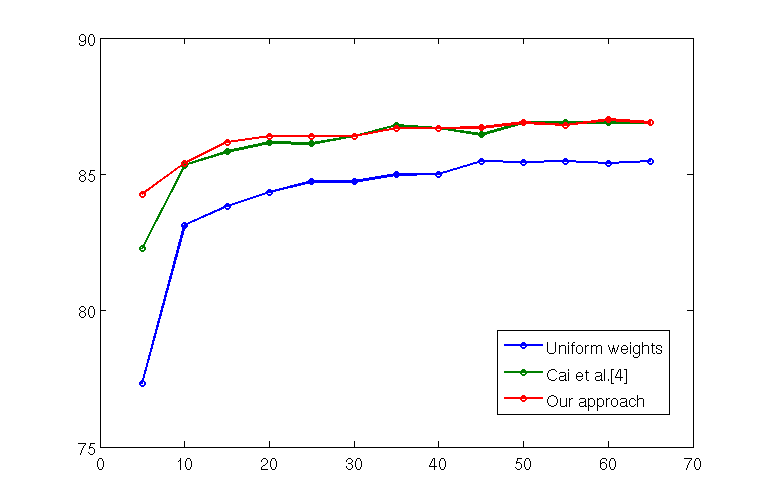
on the test set for both approaches is shown in Fig.2 at
varying training set size. Results are averaged on 100 runs.
As baseline we considered a uniform weighting scheme
i.e. all weights are set to 1. Fig.2 clearly shows that the
weights learning algorithms outperform uniform weighting in
retrieving the correct histogram class. Moreover the proposed
approach is more effective than the algorithm in [7] for small
datasets. To perform these experiments we considered the
optimization problem proposed in [7] and we solved it with
a stochastic gradient descent algorithm similar to Algorithm
(1). However we could not use this algorithm for loop closure
experiments since its computational cost is prohibitive for
medium and large sized training sets (N > 100).
Fig.2: Synthetic data: Classification accuracy at varying
training set size.
RAWSEEDS dataset
The RAWSEEDS dataset collects data from different sensors
along several robot trajectories recorded at the Bicocca
University in Milan. The paths include one floor of an office
building connected by a glass-walled bridge to the floor of
another building. The former is characterized by various
corridors very similar to each other and a wide hallway
with many different architectural features such as columns,
chairs, staircases and elevators. The latter contains a library
occupying most of the floor.
(a)
(b)
(c)
(d)
Fig.3: RAWSEEDS dataset sample images
Each path has an associated
ground truth, obtained through a SLAM algorithm fusing
vision-based information with data collected by four Sick
LMS200 laser range finders. In our experiments we used the
stereo camera recordings of two different paths. The images
were collected at 15 fps with a resolution of 640x480. We
took a subset of these images to generate a visual vocabulary
with k = 10 and L = 3. We used the same vocabulary for
experiments on both paths. We also selected a small subset of
250 labelled images from path 1 as a training set in order to
learn the word weights with Algorithm (1). Then to perform
loop closing experiments we sub-sampled respectively the
34026 and 22059 images of Path 1 and Path 2 at 1 fps,
obtaining about 2000 images for each path. This dataset has
been previously used by other works (e.g. [3]). However our
results are not directly comparable to [3] due to a different
experimental setup.
We applied the proposed weighted BoW strategy to detect
loop closures and compared its performance with those
obtained with BoW and TF-IDF weighting scheme. The
performances of both approaches are shown in Table I and
Table II respectively for Path 1 and Path 2.
The tables clearly show that for both paths learned weights greatly
increase precision with only a slight decrease in recall. In
particular the number of false positives is proximal to zero:
a situation that is desirable in SLAM systems, as previously
noted. The last column of the Tables I and II shows that
further improvements can be obtained by adding a geometric
consistency check as explained in Section 2.3. In the tables
these results are shown separately to draw attention to the
effects of the weights learning scheme.
Our experimental results show that our approach guarantees
better recognition performance not only on Path 1 from
which the training set is extracted, but also on Path 2, and in
general to other trajectories corresponding to a robot moving
around in the same area. This demonstrates that our approach is quite robust
to small changes in the environments and under different
light conditions.
We also compared our approach with the results we
obtained using a large vocabulary (k = 9 and L = 6)
and TF-IDF weighting scheme. The associated results are
also shown in Tables I and II. It is noteworthy that our
approach guarantees better performance and in particular low
false positives even using a smaller vocabulary. Moreover
since the computational cost of pairwise image comparisons
is proportional to the vocabulary size, we obtain not only
an increased detection accuracy but also a shortening up
at recognition time. A further speed up is also obtained
because, after learning, many computed weights are equal
to zero (about 30% for this dataset), i.e. a large number
of words are not considered in computing image similarity.
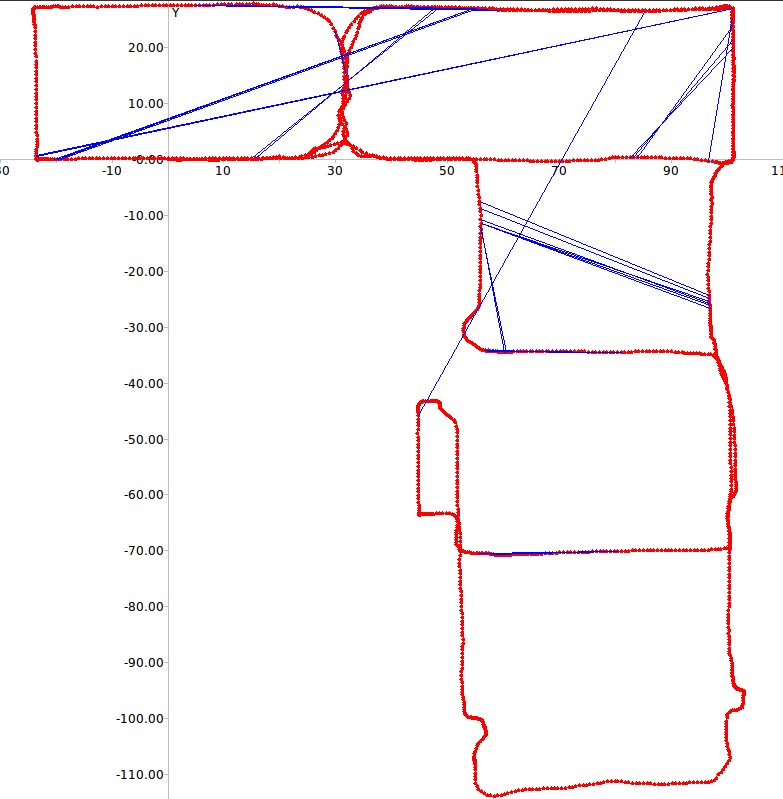
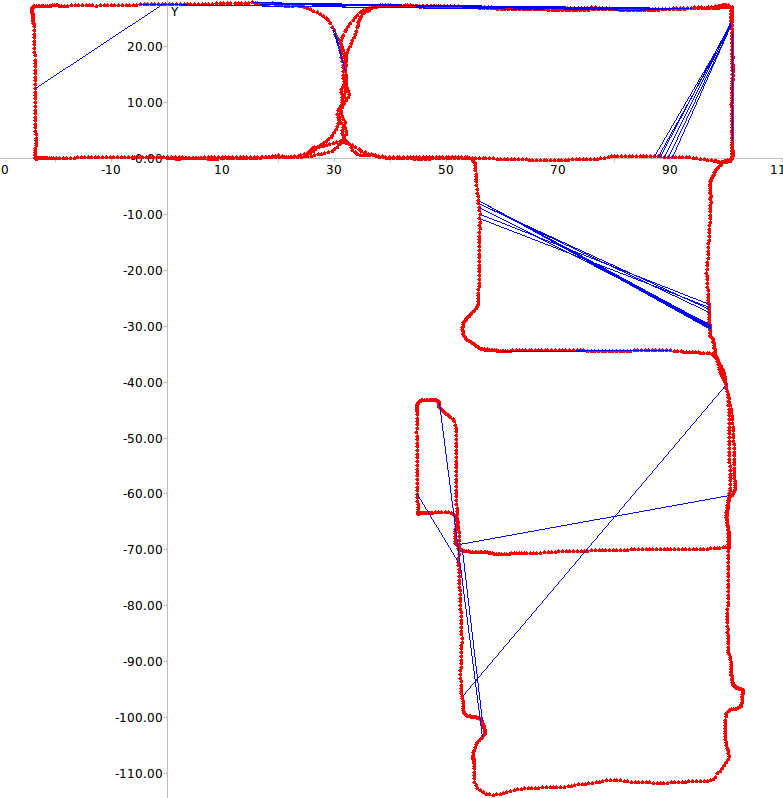
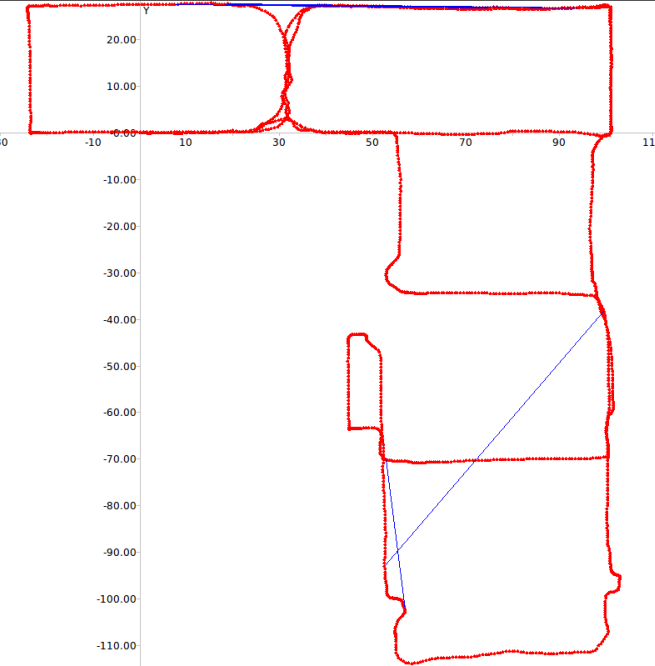
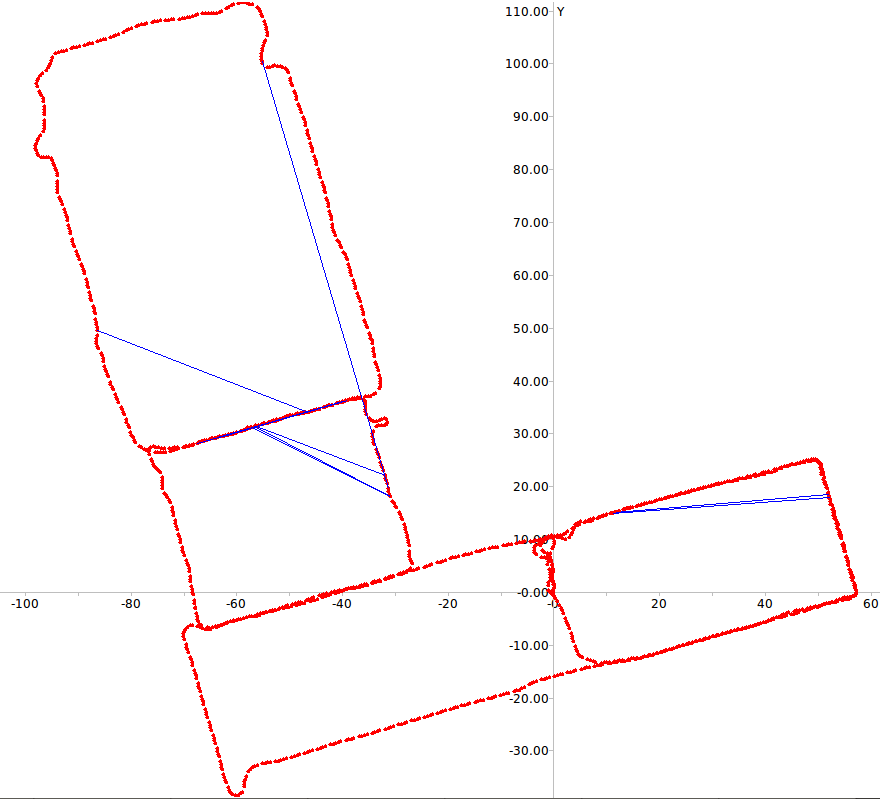
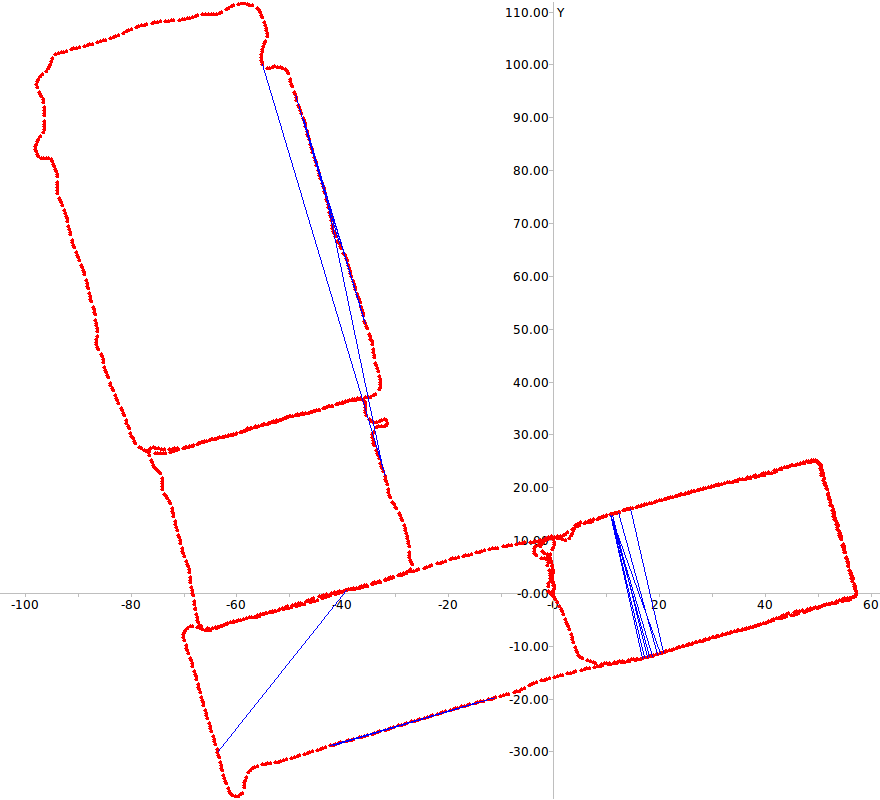
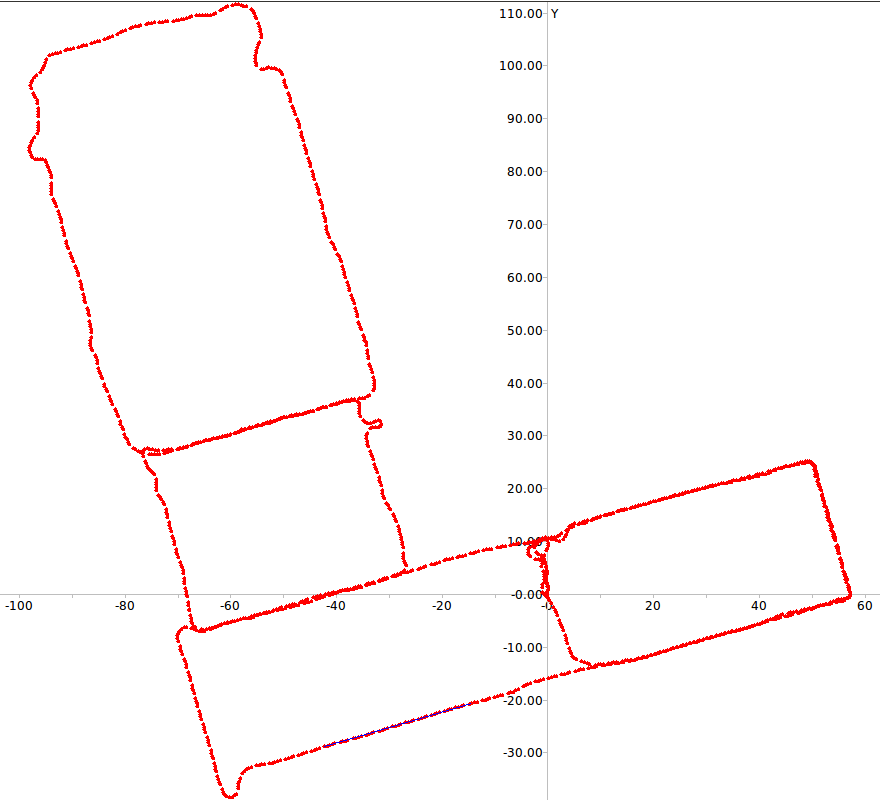
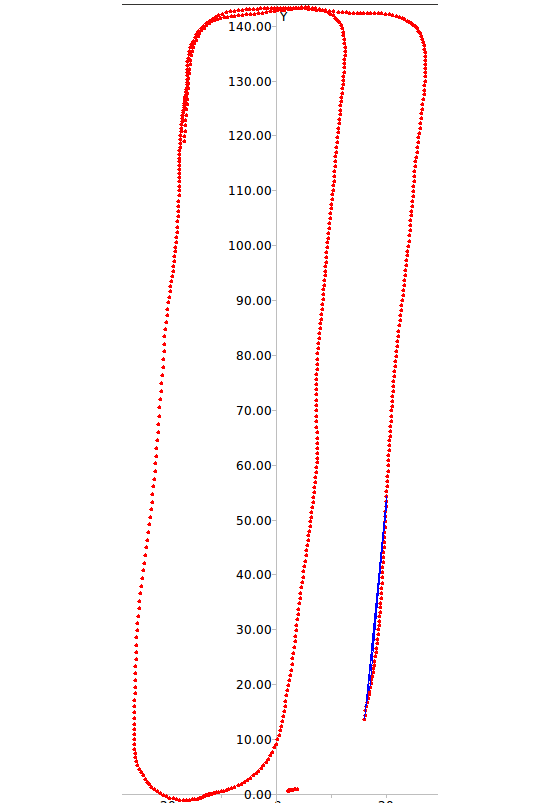
Figure 5 depicts the errors in loop closure detection (blue
lines) and the trajectory of the robot (red line) for the two
paths considered. It is easy to see that with learned weights
few incorrect loop closures occur even in the case of this
challenging dataset where several frames depict the very
similar corridors.
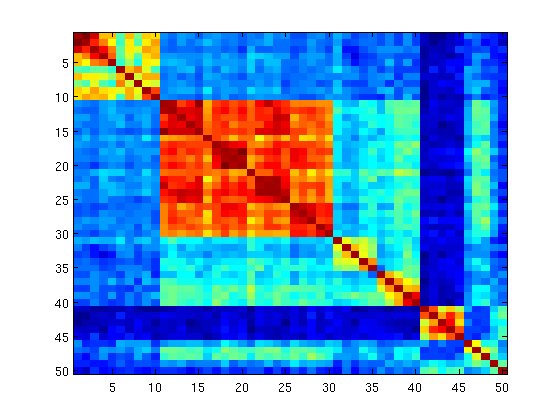
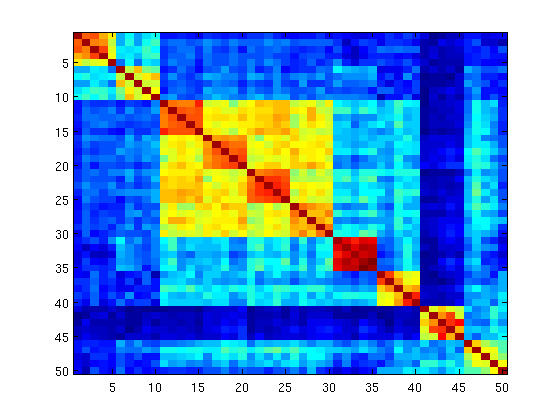
To further visualize the effect of weighting words we also
constructed similarity matrices from the BoW histograms of
the images from the training set. Adjacent rows/columns in
the matrix correspond to neighbouring images (i.e. images
associated with the same location). A perfect similarity
matrix should have a blocky structure, with images of the
same class being very similar and representing a diagonal
block. Figure 4 depicts the image similarity matrices without
and with weights learning. It is clear that the block diagonal
structure is much more visible in the right image, meaning
that learning weights is effective in making BoW histograms
with the same label more similar to each other.
(a)
(b)
Fig.4: RAWSEEDS dataset: similarity matrix (a) before and (b) after weights learning.
A final remark concerns training set creation. In our experiments
we tested several possible training sets of varying
size (100 < N < 1000) and we obtained similar results
to those reported in Tables I and II. This demonstrates that
this choice is not particularly critical. Learning weights is
generally beneficial for improving recognition accuracy as
long as the training images are representative of the overall
scenario in which the robot is moving.
Fig. 5: RAWSEEDS Dataset: errors in loop closure detection in Path 1 (top) and Path 2 (bottom)
Path 1 with 9^6 vocabulary
Path 1 with 10^3 vocabulary
Path 1 with weighted vocabulary
Path 2 with 9^6 vocabulary
Path 2 with 10^3 vocabulary
Path 2 with weighted vocabulary
Málaga Parking dataset
The MALAGA dataset (Blanco et al.) is a publicly available set of
images taken by a robotic platform in the parking lot of
the Computer Science School building of the University of
Málaga. The presence of several similar elements,e.g. trees or
buildings, and even of many dynamic objects such as cars or
pedestrians, makes some areas in the parking lot very similar
to others (see Fig.6).
(a)
(b)
Fig.6: MALAGA dataset sample images
This greatly increases the difficulty
of the loop closure task. The dataset has a centimeter accuracy
ground truth, robustly computed from the three
RTK GPS receivers. We used two different paths (2L and
6L) and we sub-sampled the image sequences, obtaining
about 1500 images for each path. The image resolution is
1024x768. As before, we built a vocabulary (k = 10 and
L = 3) and we extracted a training set of 250 images
from Path 2L to train our weights learning algorithm. Tables
III and IV show the results for both paths.
These paths
and the associated loop closure errors are represented in
Fig.7. As for the RAWSEEDS dataset our approach improves
recognition performance with respect to BoW with TF-IDF
weighting scheme for the same vocabulary and even for a
larger vocabulary. In particular, for both the RAWSEEDS and
the MALAGA dataset there is always a great improvement
in precision with a small decrease in recall. Regarding the
computational cost, in the MALAGA dataset about 12% of
the learned weights are equal to zero implying a considerable
speeding up of test time.
Fig. 7: Malaga Dataset: errors in loop closure detection in Path 6L (top) and Path 2L (bottom)